
Why LLMs are Significant: My Response to Freddie deBoer on AI
An AI explainer framed as a rebuttal

Freddie deBoer, a writer whom I respect profoundly, has recently written a couple of times about AI. His posts (1, 2, and 3) discuss modern AI as nothing more than a probabilistic model, and (to paraphrase) therefore little more than a parlor trick. While it is true that modern large language models (LLMs) are purely probabilistic, I find his thinking on them somewhat confused.
My original goal in writing this post was going to be an explanation of how LLMs are similar/different from human cognition and why that matters. However, the more carefully I went over his arguments, the more I realized that the biggest issues weren’t just philosophical disagreements. In actuality, I believe that FdB has some significant misconceptions about what these models actually are and how they work, not to mention the broader scientific context that has emerged in the last four or so years.
And so, while this post will still be framed as a rebuttal, it is really more than anything an explanation of why the newest advances in AI are so significant. As such, it ought to be very digestible to anyone with passing interest in that question, whether or not they read Freddie deBoer’s blog.
Before I get started, though, I want to get one or two things out of the way by putting my response in context. Freddie deBoer writes that “Every time someone points out that these current ‘AI’ systems are not in fact thinking similarly to how a human does, AI enthusiasts point to improving results and accuracy, as if this rebuts the critiques.” I want to respond to this upfront by saying that there is more being discussed here than just improved performance. As I will explain, right now AI is improving not just in performance but in the very nature of what tasks they are able to accomplish.
Which brings me to an extremely important distinction I want to make early: the one between “reasoning” and “consciousness”. Reasoning is dynamically applying knowledge of the world to solve problems in a logical fashion, and it’s a sensible thing to ask about in an AI system. Consciousness, the act of possessing subjective experiences, is not. The fact of the matter is that humanity doesn’t really know what consciousness is. It can’t be observed, measured, or even explained. For that reason, I’d like to keep it out of the discussion entirely.
So when FdB says “the accuracy of the output of a machine learning system can never prove that it thinks, understands, or is conscious,” My response is that he’s right about “consciousness” but wrong about “understanding,” and I’d like to draw a line between those two terms. I like the analogy he uses shortly after, when he compares a plane and an eagle and says that it’s missing the point to claim that the plane is faster. Maybe that’s true for the question of “consciousness”, but in this analogy I think “reasoning” is the appropriate analog of “flying speed.” And if it isn’t, then what exactly are we even talking about here?
Finally, I am aware that a lot of people are seriously over-stating what AI is right now, making absurd claims and suggesting all kinds of crazy things. And it doesn’t help that the statistical models involved have been named “neural networks,” further mystifying them. But even though crazy people will always exist and Silicon Valley will always exaggerate, the fact remains that something very significant is lurking below all that hype. I don’t want to have to defend every ridiculous thing anyone’s ever said on the topic, and I’m not trying to say everyone needs to jump onto the bandwagon. All I’m saying is that there really is something important happening right now, and it’s worthwhile to understand that.
LLMs Are Not Databases
Freddie deBoer often refers to LLMs as vast corpuses of data that use “vast data sets and complex models to generate a statistical association between terms.” I see this wording as implying that an LLM inherently has access to the data on which it was trained. He dances around this a few times in his first two posts, but he really makes this assumption explicit in the third, describing neural networks as “consult[ing] an unfathomably large set of texts, analyz[ing] the proximal relations between that term and billions of others, and in so doing creat[ing] a web of relationships.” This isn’t what LLMs do, except maybe in the way that humans make decisions by consulting an unfathomably large set of memories and personal experiences.1
One paragraph in particular suggests to me a certain fundamental misunderstanding of what an artificial neural network is:
Years back, Douglas Hofstadter (of Godel, Escher, Bach fame) worked with his research assistants at Indiana University, training a program to solve jumble puzzles like a human. By jumble puzzles I mean the game where you’re given a set of letters and asked to arrange those letters into all of the possible word combinations that you can find. This is trivially easy for even a primitive computer - the computer just tries every possible combination of letters and then compares them to a dictionary database to find matches. This is a very efficient way to go about doing things; indeed, it’s so efficient as to be inhuman.
So the first thing I want to make clear about LLMs and other artificial neural networks is that there is *absolutely no dictionary database* involved. What I mean by that is that neural networks emphatically do not operate by putting associations, blocks of text, game configurations, or literally anything else into a database and then looking them up. There is no “search” function in an LLM, certainly not over any of the data it was trained on.
Rather, a neural network should be thought of as a computer program, not a database. It’s something that takes an input, does a bunch of processing on it, and then spits out an output. It’s just a black box doing a bunch of mysterious multiplications and additions. If you prefer, you can imagine a giant machine with gears and other do-dads. We don’t know much about how all these pieces work or stick together; all we know is that if we drop something down the top something else will pop out the bottom.
A database by comparison would be a clerk with a filing cabinet. Ask him for what you want and he’ll rifle through until he finds it and gives it to you. In the first example, the data and knowledge is encoded somehow into the gears of the machine; in the second, it’s all just sitting there and one need only search to find it.
And I’ll add that FdB is right to criticize database-style techniques which try only to accumulate and store relations between words. Those were tried, and they do have some useful applications. But no one will ever get something like an LLM out of such an approach, and it’s a mistake to put LLMs in that same category.
Modern AI *Does* Learn Through Trial and Error
Continuing with that same quote, I noticed another arguably more profound misunderstanding:
Hofstadter’s group instead tried to train a program to solve jumbles the way a human might, with trial and error. The program was vastly slower than the typical digital way, and sometimes did not find potential matches. And these flaws made it more human than the other way, not less.
The thing is, that trial and error procedure is exactly how we train artificial neural networks. AlphaGo, the AI that beat the world champion at the game of Go2, was a neural network trained by playing millions of games against itself, improving its performance through trial-and-error. And again, I emphasize that the output was a program, not a database. It took a Go board as input and spit out a move3. The moves it spit out were determined by a single “glance” at the board, not by looking ahead, not by explicitly comparing to another game where it was in the same position. So if you’re going to say that trial-and-error learning without explicit databases or brute force searches makes it more human, then you need to wrestle with the fact modern neural networks are the literal culmination of the kind of work that Hofstadter did in that study.
And yes, this applies to LLMs as well. The procedure is considerably less complex than the one used for AlphaGo, but is fundamentally one of trial-and-error: LLMs learn by reading text and constantly predicting the next couple letters. If they predict correctly, then the neural pathways that yielded that result are enforced; if not, then they are reinforced in the direction of what it should have predicted instead. You could imagine a child trying to say a specific word like “cookie” but instead cooing out some other strange nonsense, and each time it fails its mother repeats the word “cookie” until the child finally gets it4.
Any knowledge an LLM does or doesn’t have comes from what it learned through this procedure. All of its facts and associations are encoded opaquely inside the network.
Now, could a procedure like that still memorize things? Absolutely, it’s been thoroughly proven that they can. But it’s also been proven that they don’t necessarily have to, and that when trained properly they will develop understanding of progressively more abstract concepts. As an example of the kind of the things that research has shown, the first layer of a neural network for processing images generally operates by detecting the edges between objects, the second layer might combine these edges into textures, and so on until the later layers are looking for more conceptual things like eyes or faces. This is quite well documented.
And when you look at the deeper levels of networks that process multiple things, like text and images, you find that the same neurons activate for the same concepts. For example, an image of Spider-Man produces the same neural activations as the word “spider.”5 This fact is related to why it’s possible to create generative AIs like DALL-E 2.

But Why All the Hype?
If you really want to understand why everyone is taking LLMs so seriously, then it’s important to understand the concept of “scaling laws.” These are, in my opinion, one of the most fascinating and frankly under-discussed things about LLMs (at least in popular media).
In essence, a scaling law is an equation that tells you something of the form “make the network this big, train it for this long on this much data, and it will achieve this level of performance.” (I will explain “more performance” in the next section)6. It is best explained with these graphs, taken from the paper that originally introduced the concept in the context of LLMs. You need only observe the shape of the graphs, don’t worry about the rest.7

In this image, the y-axis is performance (lower is better), and the x-axes are each of the variables that can change (amount of computation, amount of data, network size). Notice how the lines are nearly completely straight. What that means is that not only are the effects of changing things predictable, but so long as the scaling laws hold we can build networks that are arbitrarily powerful. The only limitation would be the necessary engineering and resources to actually build the thing.
But of course, it seems obvious that at some point these laws would no longer hold, and before the invention of the Transformer (the type of neural network which powers LLMs) the idea of scaling law seemed unlikely; performance would very quickly plateau past a certain point and throwing more data/computation/scale at the problem did not help.
But transformers proved different. You make them bigger, they get smarter, period. OpenAI was able to predict the exact performance of GPT-4 before they even trained the thing. It still seems impossible that the law could apply forever, but even at the ridiculous scale of GPT-4 there has been quite literally no indication of any impending slow down. You can hopefully see why that makes this discovery so significant. And yes, there could be some unforeseeable wall just around the corner, but at this point all evidence suggests that it’s still quite far away, possibly too far to ever reach.
“Performance” Translates to Actual Abilities
But what does “more performance” actually mean in this context? Technically, what we’re measuring is how well the network predicts the next couple letters in a sequence of text. By itself, that doesn’t necessarily correspond to anything useful.
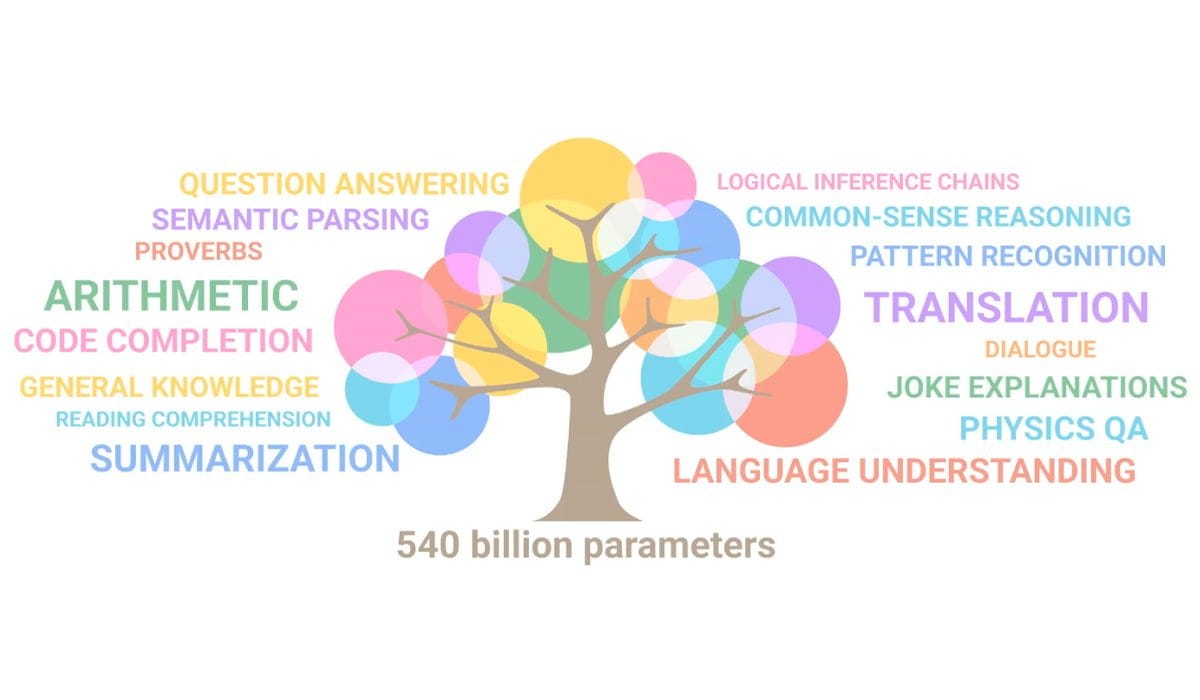
But in practice, what we observe is there are “emergent abilities” as the network gets larger. GPT-2 could not perform basic arithmetic, but GPT-3 could perform five-digit addition and two-digit multiplication on combinations of numbers it had verifiably never seen before. GPT-4 can do calculus. These are things we can measure, and they are abilities that seem to emerge spontaneously. This gif from Google nicely illustrates this phenomenon (“parameters” are the units we use to measure the size of neural networks):

Each little circle in this gif represents the LLM’s performance on various tasks. These tasks are actual quantitative assessments, where performance can be rigorously measured. More circles appear as the network gets larger because it gains the ability to solve problems it could not have hoped to solve previously, despite the fact that nothing has changed except the size of the network. And it’s important to emphasize that the scaling laws tell us nothing about this phenomenon. The only way to know what abilities will spontaneously emerge is to actually build the thing and check!
I really do want to emphasize that this is more than just hype. It’s strange, completely real, and very much uncharted scientific territory. FdB criticized the idea of emergent properties as un-rigorous and unscientific, and five years ago that stance would have been at least defensible, if not a bit extreme. But things have changed. The people who hypothesized emergent properties aren’t hypothesizing them any more, they’re observing them.
Now combine this with the fact that ChatGPT is already at a point where it’s good enough to change a significant number of industries - teaching, programming, law, etc. - and you realize there’s a very good chance this is just the beginning. If no new AI innovations came out in the next ten years, the scaling laws alone would likely be enough to build systems with new properties that made them vastly more useful than modern LLMs.
Okay, But do LLMs Have a “Theory of the World”?

And now at last I feel equipped to address FdB’s thesis. His entire argument centers around this idea of “theory of the world.” In his words, it is “a sense of how the universe functions that informs our linguistic parsing.” I don’t intend to argue that LLMs have a theory of the world comparable to that of a human, certainly not any LLMs that exist now.
But the question I’d like to ask is what if “theory of the world” isn’t an either-or thing? What it’s a spectrum instead, where some theories of the world are stronger or larger than others? That certainly seems more likely. A child would have a much reduced model of the world compared to an adult, not just because their pool of knowledge is smaller but also because they can only make much simpler inferences.
And what if this isn’t a one-dimensional spectrum either, but there can be different types of theories of the world? A dog probably has some model of the world, but they can’t possibly make the connections a human can. If intelligent aliens visited Earth tomorrow and began studying it, they would probably develop their own theory of the world, and it would likely look very different from ours. It would probably have different strengths and weaknesses, making mistakes we would never make while also making connections we’d never expect.
And if we can agree that this is at least plausible, that it’s possible to have just “a little” theory of the world, then I think there’s a good argument that modern LLMs have that, but in a way very different from our own.
Yes, some of their performance may be regurgitating what’s in the training set, but certainly not all of it. As I said, GPT-3 solved math problems that were unambiguously not in the training set, meaning it had to have developed a working knowledge of the underlying principles. GPT-4 could turn mathematically correct proofs into Shakespearean prose (see above). At some level, that’s “just” taking the ideas and translating them into another domain. But at another level, there must be something like understanding happening, even if only at a surface level, because how else could the mathematical ideas remain intact? And sure, maybe someone’s set that proof to Shakespeare before, but this copy is unique. And we can prove that: it’s not like we can’t google the prose and see that it isn’t plagiarized.
But if we can concede that LLMs are on the low end of theory of mind spectrum, or at least almost on that spectrum, then I think the broader context makes it clear why this is a big deal. Given the emergent effects of scaling doesn’t it seem at least *possible* - not guaranteed, but not entirely unlikely either - that we are not too far from something with a broader theory of the world? What if we’re only a couple more emergent effects away? Maybe it’ll still be far from human level, certainly it won’t behave in a human way or make the types of mistakes humans make, but why would we require that it have exactly human-like intelligence anyway? That seems too limiting.
Good Theories Need to be Falsifiable
I’d like to finish with one more point, more directly aimed at Freddie deBoer‘s post. In his most recent post on the topic, FdB devises the “Almond Butter Test.” The idea is that a human who never heard of almond butter could still reasonably guess what it is by making inferences about the world and concluding that it’s probably similar to peanut butter. In his own words:
I know that almonds are a kind of legume and also fall under the category of food, and that peanuts are a kind of legume and food, and that peanuts get turned into peanut butter, and I extrapolated from those facts to assume that almond butter is a product like peanut butter but made from almonds.
Now, the biggest problem here is that I don’t really believe that that’s how he actually guessed what almond butter was, at least not explicitly. For one thing, almonds aren’t legumes. That’s not a dunk on him, I literally hadn’t even heard the word “legume” myself before reading that post. It is, however, an illustration of the fact this explicit chain of logic probably had nothing to do with his reasoning. I never heard of legumes but I’m pretty sure I also correctly inferred the meaning of Almond Butter the first time I heard the term.
What I think actually happened was almost purely probabilistic. It was just a bunch of correlations. He didn’t work things out piece by piece, his brain just used its own internal correlations to conclude “that kind of sounds like peanut butter” without really going through any other motions.
And honestly, maybe that’s all FdB meant, I’m not totally sure. Either way, I personally believe that that correlational process is exactly how an LLM would guess what almond butter is if it hadn’t heard of it (sadly, I am not creative enough to test this, as any concept I imagined was findable with a google search). But even if LLMs didn’t reason that way, there would be no way to know. That’s the real point here: “The Almond Butter Test” is a test of internal processes only, and like questions of consciousness there is simply no way to know if anything actually passes it.
And so I return at last to FdB’s comments about why AI systems will never have a theory of the world:
Every time someone points out that these current “AI” systems are not in fact thinking similarly to how a human does, AI enthusiasts point to improving results and accuracy, as if this rebuts the critiques. But it doesn’t rebut them at all. If someone says that a plane does not fly the same way as an eagle, and you sniff that a plane can go faster than an eagle, you’re willfully missing the point.
The reason people keep trying to show improved performance is because it’s something you can measure, and because with that performance comes real-world applications of this technology.
But as Freddie deBoer presents it, no matter what evidence anyone shows him, he’ll always be able to claim “that’s not a true theory of the world.” I think that’s just not playing fair. If you refuse to give your opponents a test that they can pass, and which they can prove they’ve passed, then that means your argument is unfalsifiable. And as any scientist will tell you, a good theory needs to have an experiment that can prove it false. Otherwise what’s the point of it?
Technically, there are LLMs which can search the internet. But ChatGPT doesn’t do that. And even if it did, that’s a completely separate process from actually running the LLM. What’s actually happening is that LLM is given access to a search engine, and then decides whether or not to use it.
For those who don’t know, Go is a game that holds a place similar to Chess in many Asian cultures. It is purely strategic, but unlike Chess there are far too many moves for a computer to win by brute force. Just before AlphaGo beat the world champion, it was assumed a good Go-playing AI was at least 10 years away.
Technically, AlphaGo did have a “game tree” feature that allowed it to look ahead at moves to see their outcomes. However, even without it, it still performed almost as well. More importantly, future iterations, like MuZero, achieved superhuman performance even without any look-ahead features.
Also, if you’ll permit me to be a bit salty, why is it that we can say Hofstadter’s machine is more human because it makes mistakes, but LLMs are less?
These equations are empirical, they were found through experimentation and don’t have any underlying principles, so they aren’t really “laws” the way gravity might be.
Source: Kaplan et al. https://arxiv.org/abs/2001.08361
I appreciate this post and will now make an incredibly pedantic point, not unlike your observation that almonds aren't legumes. But perhaps it has larger implications: The proof supplied above is not Shakespearean and is not prose. It is poetry that uses a few archaisms that code as "olde timey" and thus as Shakespearean to those largely ignorant of Shakespeare. Shakespeare's plays do not generally rhyme but are in blank verse (unrhymed iambic pentameter) and they feature original metaphors and complex word play, much of which is lost on modern audiences that aren't reading footnotes. This poem is doggerel of the sort that my sister-in-law writes for fun family birthday cards. No one would mistake it for Shakespeare or even an imitation of Shakespeare.
Is the lack of understanding what "Shakespearean" means an indicator of something more fundamental than an early stage of development? I suspect not, but I'd like to see those with more knowledge address the question. ChatGPT generates a lot of on-command poetry, but it is all consistently bad poetry--though fun--and rarely, if ever, a reasonable imitation of a prompted style. I don't expect a "Shakespearean" poem to rise to the level of Shakespeare, but it should at least read like something someone in the Elizabethan period might have written.
This post reminded me that the book "Blindsight" by Peter Watts exists; in his own words "a whole book arguing that intelligence and sentience are different things". He argues via sci-fi that humans attribute too much agency to our conscious minds; instead most decision-making is done subconsciously, and our consciousness is just along for the ride. ("If the rest of your brain were conscious, it would probably regard you as the pointy-haired boss from Dilbert.")
Lots of fascinating references for further reading at the end: https://www.rifters.com/real/Blindsight.htm
Metzinger's "Being No One" was a major influence: https://mitpress.mit.edu/9780262633086/being-no-one/